Spark Streaming를 통해 실시간 분석 애플리케이션을 만들 수 있는데, 스트리밍 데이터 소스 중 하나로 Kafka를 사용할 수 있다. 이 포스트에서는 Kafka가 필요한 이유와 Spark Streaming과 연동하는 방법을 알아보고자 한다.
Kafka 등장 배경
데이터 파이프라인의 복잡성을 줄이고 원격 통신을 쉽게 할 수 있게 만들어준다. 그림으로 보자면,
아래와 같이 기존에 복잡했던 파이프라인을

이렇게 단순화 시켰다고 생각하면 된다. 데이터를 요청하는 Consumer와 메시지를 보내주는 Producer로 나누어진 구조에서 매개자 클러스터 역할을 하는 것으로 보인다.

Kafka 컴포넌트
- Broker : 위에서 봤던 그림에서 메세지를 양 쪽에서 잘 주고 받을 수 있도록 하는 책임이 있다. 보통은 이 Broker들을 여러 개 두어 클러스터를 이루게 한다. 따라서 zookeeper로 서로의 정보를 조율하는 과정이 필요하다. (새로운 Broker 등장, 특정 Broker의 실패 등에 대한 보고)
- Message : byte array, JSON Avro 등등 어떤 format이든지 가능하다.
- Topic : Message들은 각각 어느 Topic에 속하게 되어있다. Topic 이라는 기준 안에서 카테고리화되고 publish 된다. 몇가지 partition으로 나누어진다.
- Producer: Message를 하나 또는 여러개의 topic에 publish하는 프로세스들이다. Kafka에서 data stream이 나오는 근원이다.
- Consumer: 하나 또는 여러개의 Topic을 subscribe함으로써 데이터를 topic으로부터 읽어오는 프로세스들이다.
- Paritions: 각 Broker들은 몇가지 partition으로 나누어져 있고, 각 partition들은 topic에 대한 리더일 수도 있고 복제본일 수도 있다. 이는 확장성/중복성의 효과를 준다.
Kafka 아키텍쳐
Producer, Broker, Consumer 순서로 동작 과정을 알아보겠다. Producer, Broker, Consumer 모두 여러 개로 이루어진 그룹을 이루고 있다.

- Producer: producer들은 message를 topic으로 보내는데, topic 별로 어느 parition에 message를 보낼 것인지 또한 결정한다.
- Broker: producer로부터 message를 받으면 offset를 할당한다. consumer부터 fetch 요청이 올 때마다 반응한다.
- Consumer: topic들을 subscribe하면서 message들이 생성된 순서대로 읽어내려간다. message들의 offset을 따라가면서 이미 읽혀진 message와 아닌 message를 구분 할 수 있다. 같은 키를 가진 message들은 기본적으로 같은 consumer에게 간다. 즉, 각 partition들은 하나의 consumer에 의해서만 consume 되어야한다.
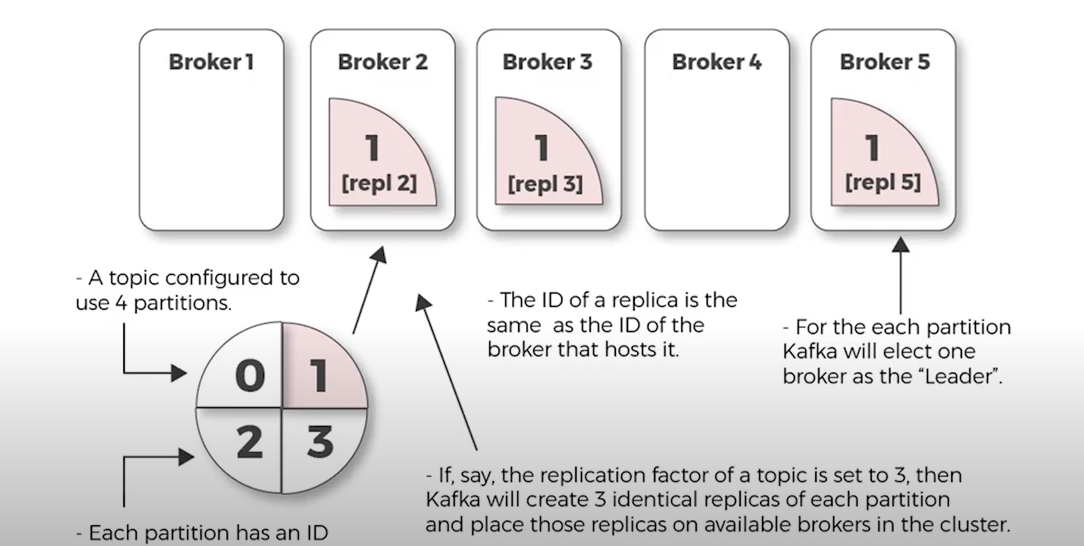
아래는 topic이 여러 개의 partition으로 나뉘고, 할당 가능한 Broker가 각 topic의 partition을 맡는다는 것을 알기 좋은 그림이다.
Kafka 띄우기
- zookeeper start
zookeeper-server-start.sh kafka/config/zookeeper.properties - kafka server start
kafka-server-start.sh kafka/config/server.properties -
jps로 QuroumPeerMain과 Kafka가 있는지 확인
- topic 생성 (이때, 프로그램에서 사용되는 topic 명과 동일할 것)
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partition 1 --topic mytest
여기부터는 애플리케이션의 성격에 따라 달라지나, 데모 앱이라는 것을 참고해서 보며 되겠다.
- producer start
kafka-console-producer.sh --broker-list localhost:9092 --topic mytest
hi hello
how are you ....
콘솔 명령어를 쓰는 것은 실제 서비스로 사용하기는 부적합하나, 테스트 용도에서는 충분하다.
- consumer start
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic mytest --from-beginning
또는 여기서 부터는 Spark Streaming 애플리케이션을 통해 producer에서 생성된 message들을 확인 할 수 있다. 아래에서 확인해보자
Spark Streaming WorkFlow
Spark Streaming 은 live input data stream을 받아야 하고 그 데이터들을 작은 배치단위로 나눈다. 그 작은 배치 단위의 데이터들이 spark engine을 거쳐 처리되는 것이다.

간단한 스트리밍 예제를 살펴보자.
object kafkar {
def main(args: Array[String]){
val conf = new SparkConf().setMaster("local").setAppName("kafkaex")
val ssc = new StreamingContext(conf, Seconds(2))
// topic name is 'mytest'
val kafkaStream = KafkaUtils.createStream(ssc, "localhost:2181","spark-streaming-consumer-group",Map("mytest"->5))
kafkaStream.print()
ssc.start
ssc.awaitTermination()
}
}
출처: www.youtube.com/watch?v=2z6scTH_C4c
'programming > Big data' 카테고리의 다른 글
| Spark와 직렬화 - transient lazy val 패턴의 도움받기 (0) | 2020.05.27 |
|---|